趣味で開発しているPuppeteerを使ったPDFサーバーhc-pdf-serverで一部分をnpmにパッケージとして公開しています。
これ↓
www.npmjs.com
FastifyからPuppeteerを通して、Headless ChromeのPageを使用できるプラグインです。
名前の通り速いFastifyの長所を殺すこと無く、起動しておくPageを増やすことで大量リクエストもさばけそうな気がします(実戦経験はない)。
PDFだけでなく、スクリーンショットとか、JavaScriptでできたHTMLを取得したりいろいろできるよ!
Puppeteerとの連携部分はもともとFastifyのプラグインとして作っていたこともあり、
また超絶頭のいいと思われる見知らぬプログラマからすばらしいプルリクを頂いて強いプラグインとなったという理由もあり、
次もPuppeteer + Fastifyで何か作ろうと思っているのもあり。
で、npmにパッケージ公開してそれを使ってみたら、いろいろ世界の見え方変わった気がしたのでかなりおすすめです。基本無料です。
細かい説明は他にあるので、ざっくり流れを忘れないようにメモ。
レポジトリを分ける
既存のアプリケーションからの分離なのでまずはこれでした。
必要最低限なファイルや設定で新しいレポジトリをつくり、package.jsonに必要な情報を書きます。
この記事を参考にしました。
qiita.com
nameには最初でグローバルを汚すのも申し訳ないのでscopedと呼ばれる@uyamazak/をつけました
package.json
"name": "@uyamazak/fastify-hc-pages",
TypeScriptのコードで、jsはレポジトリに含まれていないため、prepublishOnlyでビルドするようにしました。
package.json
"scripts": {
"build": "rm -rf ./dist && tsc",
"prepublishOnly": "npm run build",TypeScriptでnpmライブラリ開発ことはじめ - Qiita
あとmainのパスをちゃんとやったりぐらいかな?
ここらへんで普段意識していなかったpackage.jsonの項目を理解し、意識できるようになった気がします。
GitHubからインストールして動作確認
それっぽいものができたら、npmjsで公開する前に自分のGitHubレポジトリにプッシュしてそこからインストールして試します。
yarnでGitHubのレポジトリからインストールを初めて使いました。
$ yarn add https://github.com/uyamazak/fastify-hc-pages
package.jsonにこんな感じで入ります。
バージョンの数字の代わりにURLが入るんだなぁ。ブランチとかの指定もできそう
"dependencies": {
"@uyamazak/fastify-hc-pages": "https://github.com/uyamazak/fastify-hc-pages",
"fastify": "^3.13.0",型定義が吐き出されずに困ってましたが、原因は拡張子を.d.tsにしてたため、というしょうもないミスでハマってました。
ここらへんでnpmパッケージがどうインストールされるかとか、かなり理解できた気がします。
npmjsに登録したり、ローカルでログインしたり、READMEとか準備
まあ普通にやるので割愛。
GitHubに吸収されて1年経つので、アイコンはGitHubの使えるのかと思ったら・・・
Gravatarェ・・・・。
太古に作ったWordPressアカウントがあった気がするけど面倒なのでそのまま。
publish !
準備ができたらpublishします。公開パッケージなのでpublicが必要です。
npm publish --access public
ここでやらかしましたが、パッケージ名が他のFastifyプラグインと違うため、変更したくなりました(最後のpluginいらなかった・・・)
でも一度公開してしまうと基本的に名前の変更、削除はできないため、新しく作って、古いのはdeprecateして放置する必要があります。
以前消えて問題になったことあるししょうがない。
↓殘骸
@uyamazak/fastify-hc-pages-plugin - npm
改めてパッケージ名を変更し、このページができました。
www.npmjs.com
自動化
それからしばらくバージョンアップのたびに手動でやってましたが、ローカルで操作するの面倒ですね。
自動でできるようにします。
npmとは別のGithub Packagesの説明が入っていて邪魔ですが、こちらを参考にしました。
docs.github.com
npm側でトークンを作り、GitHubのSecretsに入れるNPM_TOKENの設定が必要ですが、yamlは最終的にはこんな感じ。
.github/workflows/npm.yml
name: Node.js Package
on:
release:
types: [created]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
# npmに公開する.npmrcファイルを設定する
- uses: actions/setup-node@v1
with:
node-version: '14.x'
registry-url: 'https://registry.npmjs.org'
- run: npm install
# npmに公開する
- run: npm publish --access public
env:
NODE_AUTH_TOKEN: ${{ secrets.NPM_TOKEN }}タイミングは、いつものマージ、プルリクなどではなく、GitHubのReleaseという機能を使います。
ここから、タグにバージョンを入れてリリースを作成すると、自動で公開されるようになりました。
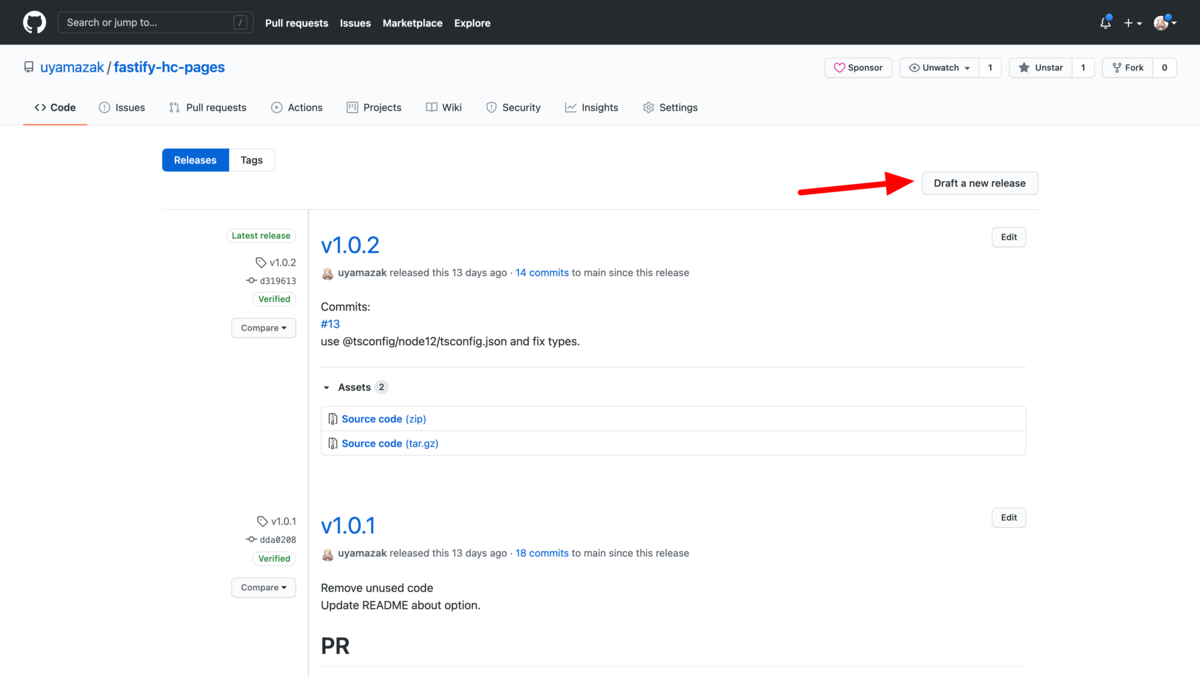
リリースの作成もcommitメッセージを集めてきたり、ある程度自動化できそうですが、しばらくはこのままでいいかな。
ここらへんで、他のレポジトリがどうnpmのパッケージをリリースしているのかを理解できた気がします。
開発を続ける
で、しばらく開発をすすめると、プラグインを更新するたびにそれを利用している元本体側も変更が必要など手間が増え、作業時間は増えてしまいます。
が、そのおかげでユーザーとしての気持ちも持つことができるので、変更する際には少し慎重になり、いい設計、コードにしたいという気持ちが強くなった気がします。
でも趣味なので作業時間はプライスレス。
おまけ: npmのWeekly Downloadsについて
ここのダウンロード数、自分しか使ってないので結構行ってますが、このレポジトリと元のレポジトリのGitHub Actionsで回しているテスト時のダウンロードもカウントされてるようです。
そのため自動でdepandabotがつくるプルリク×3環境×2Node.jsバージョン分だけこの数が増えていくことに。
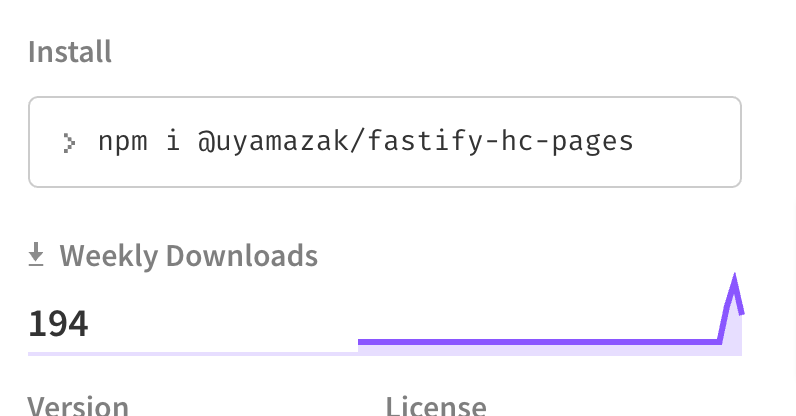
1人しかユーザーいなくてもCIなどのDLが含まれて200近く行ってしまうということで、他のパッケージのダウンロード数もそこまで参考にならないかなぁという気がします。