経緯
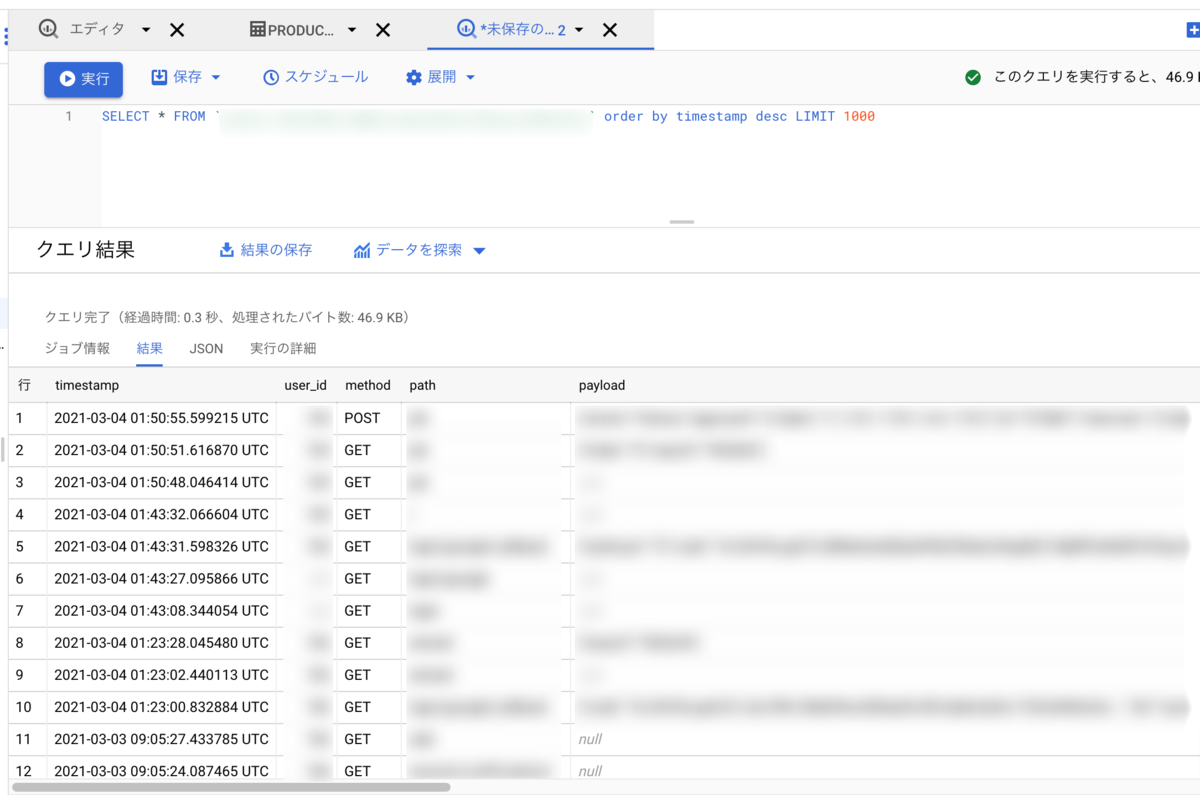
シニアジョブの人材管理システムで、もしもの時のセキュリティのために、すべての操作ログを記録することにしました。
Dataflowのテンプレートを使うことでちょっとのコードでできてしまったので、コードにならない部分の記録をするため雑にメモ。
記事中のコードは適宜はしょってるので動きません。
ElasticsearchではなくBigQueryにした理由
最初すでにElasticsearchを使っていることもあり、そちらに保存しようと思ったけど、ESの設定や維持管理、保存のためにも結構コードを書く必要もあり、
また見る際もいろいろコードを書くか、GUIのツールを使わないといけないので大変だなぁと思っているところで、以前使ったDataflowのテンプレートを思い出しました。
Google 提供のストリーミング テンプレート | Cloud Dataflow | Google Cloud
これを使うとPub/SubにBigQueryテーブルに合わせたJSONを送るだけでいろいろいい感じにインサートしたり、失敗した時はエラー用のテーブルに記録してくれたりします。
Pub/Subをかましているので、急激な負荷の変化をある程度吸収したり、BigQuery側が落ちててもリトライとかもいい感じにやってくれるはず。
これを使うことでいわゆるサーバーレス、マネージレス的に設定だけでGCP側は完了します。
LaravelのMiddlewareを作る
まずはログに必要なリクエストごとにJSONを送る仕組みをLaravel側につくります。
Middlewareを使うのが良さそうですね
使ってるLaravelのバージョンはまだ7です(もう8出てるんだ)。
Middleware - Laravel - The PHP Framework For Web Artisans
処理のタイミングがいくつかあるんですが、レスポンス終了後に行ったほうが、ユーザーへのページ表示が遅くならないので良さそうです。
ということでterminate()を使います。
大きすぎるPOSTは省略したり、内容をいい感じに整理するのに試行錯誤したけどこんな感じ。
normalize()は状況によって違うので省略するけど、ここでいい感じにしてます。
/**
* レスポンス速度の影響を防ぐため終了後にログを送信する
* @param \Illuminate\Http\Request $request
* @param \Illuminate\Http\Response $response
* @return void
*/
public function terminate($request, $response)
{
// query()とpost()の内容が重複することが多いのでマージしたものをpayloadとして保存する
$query = $this->normalize($request->query());
$post = $this->normalize($request->post());
$payload = array_merge($query, $post);
$logContent = [
'timestamp' => Carbon::now('UTC')->format('Y-m-d H:i:s.u'),
'method' => $request->method(),
'path' => $request->path(),
'ip' => $request->ip(),
'user_agent' => $request->userAgent(),
'status' => $response->status(),
];
$userId = $request->user()->id ?? null;
if ($userId) {
$logContent['user_id'] = $userId;
}
// 空配列JSONや文字列"null"をBigQueryに保存したくない
if ($payload) {
$logContent['payload'] = json_encode($payload, JSON_UNESCAPED_UNICODE);
}
}BigQueryのタイムスタンプ型に入れるときは、特殊?なこの形式にするのは気をつけないといけません。あとは普通に文字列か数字。
Carbon::now('UTC')->format('Y-m-d H:i:s.u')今回はCSVじゃないけどここに書いてるのと同じっぽい
Cloud Storage からの CSV データの読み込み | BigQuery | Google Cloud
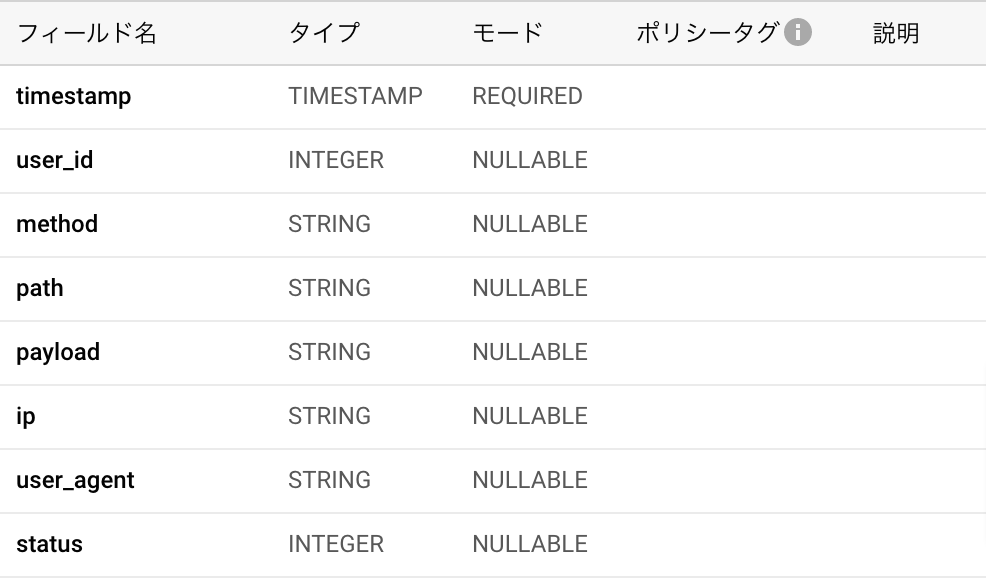
しばらく$logContentの内容をログに出しながら動作確認して良さそうだったら、これに合わせてBigQueryのテーブルを作ります。
nullになる可能性があるpayloadとかuser_idとかはBigQuery側でnullableにしておきます。
Cloud Consoleでポチポチして作っておきます。IPも無いことはなさそうだからREQUIREDでいいかなと思ったりもしたけどそのまま。
ついでにPub/Subのトピックと、それを読むsubscriptionをポチポチして作っておきます。特に設定はない。
あと専用のサービスアカウントを作り、Pub/SubにPublishできる権限だけを作って、認証用JSONをダウンロードしておきます。
ここまでできたら、Pub/Subに送信します。
Pub/Subの処理は大したことしないけど、一応Middlewareと分けるためServicceとしました。
こんなの。
<?php
namespace App\Services;
use Google\Cloud\PubSub\PubSubClient;
class GcpPubSubService
{
private $pubSubClient;
private $topic;
/**
* @param string $jsonPath
* @param string $topic
* @return void
*/
public function __construct(string $jsonPath, string $topic)
{
$this->pubSubClient = new PubSubClient([
'keyFilePath' => $jsonPath
]);
$this->topic = $this->pubSubClient->topic($topic);
}
/**
* @param string $data
* @return void
*/
public function publish(string $data)
{
$this->topic->publish([
'data' => $data,
]);
}
}こいつを使って上記terminateの最後でpublishします
$gcpPubSubService = new GcpPubSubService('保存した認証用JSONのパス', '作ったトピック名');
// 日本語見やすくするためJSON_UNESCAPED_UNICODE付けてる
$gcpPubSubService->publish(json_encode($logContent, JSON_UNESCAPED_UNICODE));
Dataflowのテンプレートでジョブを起動する
Pub/Subにエラーなく送れてそうな気がしたら、いよいよ本題のDataflowです。
「テンプレートからジョブを作成」を選んで`Pub/Sub Subscription to BigQuery`を選択します。
先程作ったPub/SubのサブスクリプションやBigQueryのテーブル名などを注釈どおりに入れます。
あと、ここで一時ファイル置き場として、Storageのフォルダが必要になりますね。
一時ファイルなので、可用性とかしらんので、安いusでregionalなバケットをつくり、tmpみたいなフォルダ作って指定しました。動作中みると空だけどいつ使うんだろう。
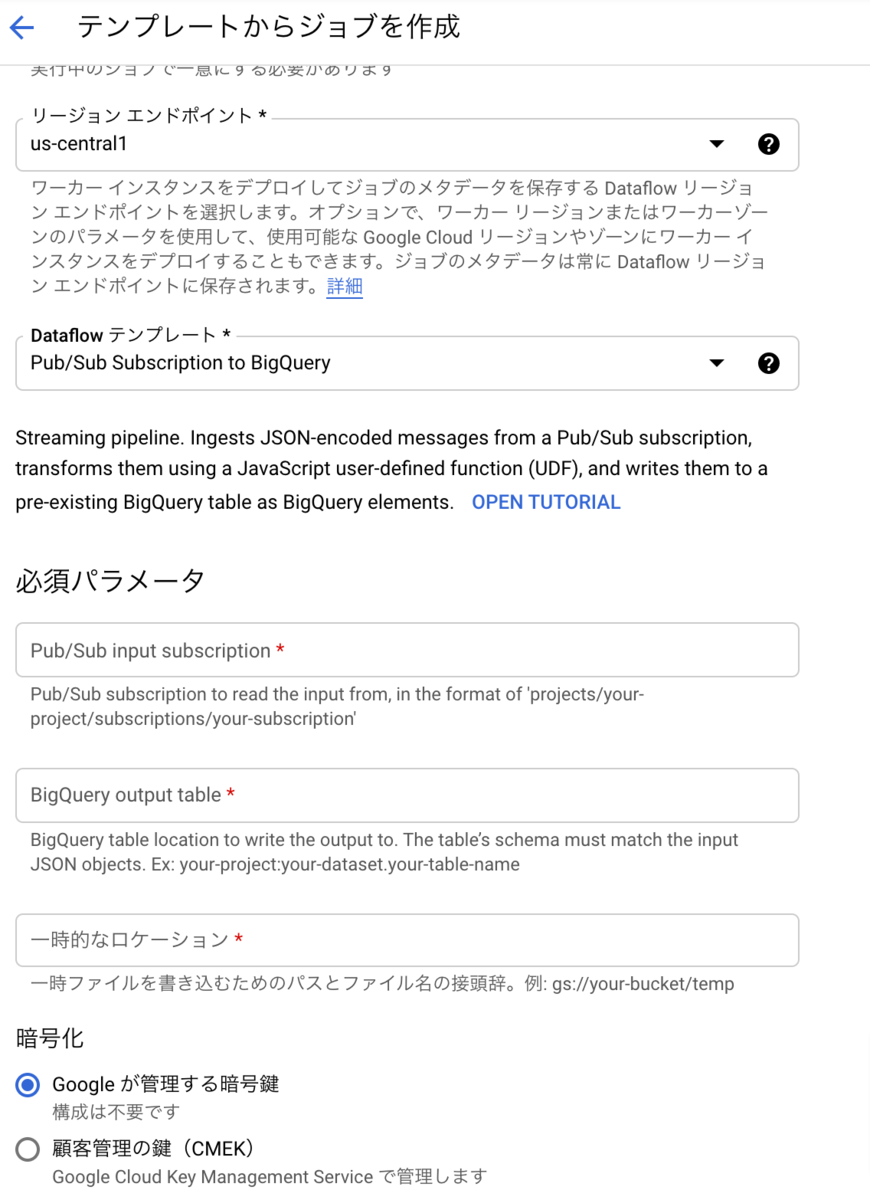
Dataflowのリソースをなるべくケチる
必須だけいれてポチっでも動いてしまいます。
しかし、多くても数十人が使う社内システムのログなのにCPU4とかHDD1.2TBとかメモリ15GBとか信じられないリソースが目に入ります。
ケチりたい。
GCPのDataflowのPub/Sub→BigQueryテンプレート、ちょっとログ取るかってだけな場合でも、デフォルトで作ると大富豪かってぐらいリソース使ってくるのは問題。隠されている設定でマシンタイプは変えれたけどHDDは減らせないのがつらい。ケチりたい pic.twitter.com/NlFjQgurpG
— uyamazak - 🐦 (@uyamazak) 2021年3月3日
ということで、Dataflowのこの隠されてる「オプションパラメータの表示」をクリックします

ここの設定は状況によって異なりますが、今回は平凡なマシン1台で十分だろってことで、
マシンタイプにn1-standard-1(ふつー)、
ワーカーの数も1、
MAXワーカーも1
で行きました。あとは空のまま。
MAXワーカー数が曲者で、デフォルトが3らしく、空のままいくと420GB×3のHDDを用意してしまいます。今回は絶対いらんやろと確信。
3度目の正直で、まあこんなもんかというリソースにできました。
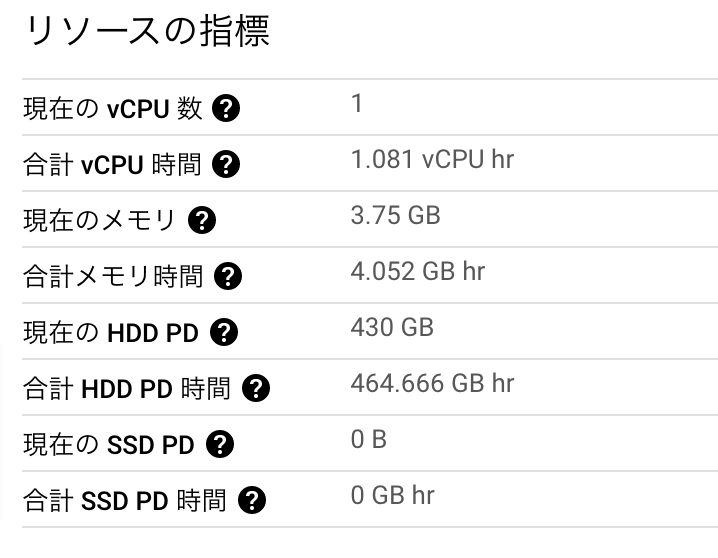
デフォルトだったら1日うん十万かそれ以上のリクエストでもさばけそうですね
トラブルシューティング
Pub/Sub送れてるのにBigQueryに入ってこないなぁってなったら、BigQueryで作ったテーブルと同じデータセットに
{yourtablename}_error_recordsというテーブルが出来ているのでこちらを確認しましょう。
型違いとかカラム名違いとかで入れられなかった場合は、その情報をここに保存してくれます
この機能も超便利。
そもそもGCPが落ちてて送れない時は諦めてSlackにでも送りつけるしかないかな。